Exploring New Possibilities with the AWS Cloud Control Collection
Exploring New Possibilities with the AWS Cloud Control Collection
We recently made available an experimental alpha Collection of generated modules using the AWS Cloud Control API for interacting with AWS Services. This content is not intended for production in its current state. We are making this work available because we thought it was important to share our research and get your feedback.
In this post, we'll highlight how to try out this alpha release of the new amazon.cloud content Collection
The AWS Cloud Control API
Launched in September 2021 and featured at AWS re:Invent, AWS Cloud Control API is a set of common application programming interfaces (APIs) that provides five operations for developers to create, read, update, delete, and list (CRUDL) resources and make it easy for developers and partners to manage the lifecycle of AWS and third-party services in a standard way.
The Cloud Control API provides support for hundreds of AWS resources today with support for more existing AWS resources across services such as Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3) in the coming months.
AWS delivers a broad and deep portfolio of cloud services. It started with Amazon Simple Storage Service (Amazon S3) and grew over 200+ services. Each distinct AWS service has a specific API with its own vocabulary, input parameters, and error reporting. As these APIs are unique to each service, developers have to understand the behavior (input, responses, and error codes) of each API they use. As applications have become increasingly sophisticated and developers work across more AWS services, it can become challenging to learn and manage distinct APIs for developers.
With the launch of AWS Cloud Control API, developers have a consistent method to manage supported services that are defined as part of their cloud infrastructure throughout their lifecycle, so there are fewer APIs to learn as developers add new services to their infrastructure.
Why AWS Cloud Control API is important to Ansible
While not directly affecting Ansible content authors automating AWS services, we believe the Cloud Control API will be beneficial in providing a better cloud automation experience.
The most noteworthy is that it enables the rapid introduction of new AWS services and implementation of new features to existing ones. This will also enable more comprehensive coverage of the vast number of AWS services available. This can be further extended to include third-party services running in the AWS cloud that have adopted the Cloud Control API.
The modules contained in this Collection are generated using a tool called amazon_cloud_code_generator - developed and open sourced by the Ansible Cloud team.
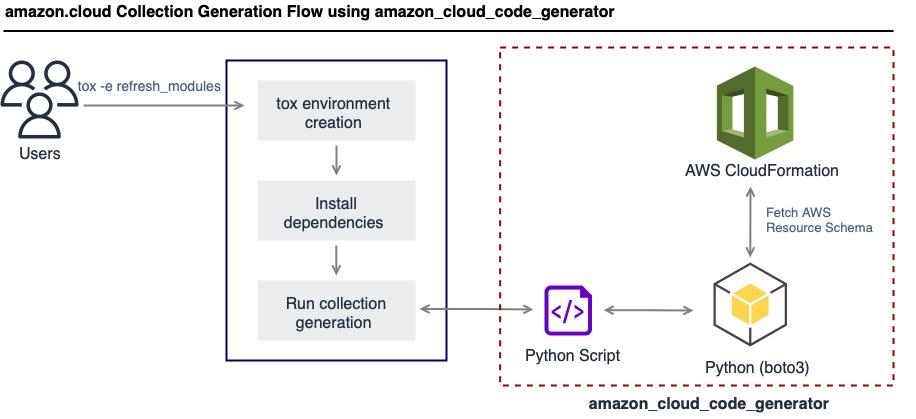
As you can see in the flow diagram, the Collection can be easily
deployed using tox -e refresh_modules, and it is generated in the
cloud subdirectory by default.
Basically, the generation process leverages some Python utility scripts that wrap the AWS CloudFormation client to scrape Resource Type Definition Schema or meta-schema for each Amazon-supported resource and performs the necessary processing to generate module documentation.
Additional processing logic generates all utilities including modules, modules_utils, and tests.
For example, module_utils contains a base class that can be used by all resource modules to
provide all the necessary methods to create, update, delete, describe
and list with the appropriate logic to wait, paginate, and gracefully
handle botocore exceptions.
Using the amazon.cloud Collection
All the modules of this Collection use boto3 Amazon Web Services (AWS) Software Development Kit (SDK) for Python and AWS Cloud Control API (CloudControlApi) client. It requires:
The basic task example
Let's take a look at a practical example of how to use the amazon.cloud Collection. Perhaps you need to provision a simple AWS S3 bucket and then describe it.
If you are already using the
amazon.aws
and
community.aws
Collections, you can see the tasks syntax is pretty much
similar.
You may notice that we no longer have
info modules,
but the "get" or "describe" and "list" features that the
info modules
were doing are handled in the main module. This certainly simplifies the
Collection usage and improves user experience.
- name: Create a simple S3 bucket with public access block configuration amazon.cloud.s3_bucket: state: present bucket_name: “{{ local_bucket_name }}” public_access_block_configuration: block_public_acls: true block_public_policy: true ignore_public_acls: true restrict_public_buckets: true register: _result_create - name: Gather information about the S3 bucket amazon.cloud.s3_bucket: state: get bucket_name: “{{ local_bucket_name }}” register: _result_info
- name: Create a simple S3 bucket with public access block configuration amazon.aws.s3_bucket: state: present name: “{{ local_bucket_name }}” public_access: block_public_acls: true block_public_policy: true ignore_public_acls: true restrict_public_buckets: true register: _result_create - name: Gather information about the S3 bucket community.aws.aws_s3_bucket_info: name: “{{ local_bucket_name }}” register: _result_info
Another relevant feature of the amazon.cloud content Collection is the structure of the returned result. Particularly, the result returned by all the available operations (present, absent, list and get or describe) is well-structured and uniform across all the modules. It always contains the identifier of the resource and a dictionary of resource-specific properties.
In this way, we can straightforwardly get the identifier of each resource and re-use it in multiple dependent resources.
This feature has definitely a positive impact on the user experience.
[ { "identifier": "090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb", "properties": { "arn": "arn:aws:s3:::090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb", "bucket_name": "090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb", "domain_name": "090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb.s3.amazonaws.com", "dual_stack_domain_name": "090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb.s3.dualstack.us-east-1.amazonaws.com", "regional_domain_name": "090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb.s3.us-east-1.amazonaws.com", "website_url": "http://090ba2aa-cc0c-5a40-9b5f-a2d2b8fc6ceb.s3-website-us-east-1.amazonaws.com" } } ]
Known issues and shortcomings
-
Generated modules like these are only as good as the API and its schema. Documentation may not be complete for all the modules options.
-
Missing supportability for important AWS resources like, EC2 instance, volume and snapshot, RDS instance and snapshot, Elastic Load Balancer, etc. Resources from some of these AWS services are expected to be supported in the coming months.
-
Idempotency (desired state) is a function of the API and may not be fully supported. In the Cloud Control API, the idempotency is achieved using the
ClientToken. AClientToken, which is valid for 36 hours once used. -
- After that, a resource request with the same client token is treated as a new request.
- To overcome this limitation, the modules present in this
Collection handle the idempotency by performing a first
get_resource(TypeName='', Identifier='')operation using the resource identifier.
-
Missing server-side pagination may have a severe impact on performance. As you may know, some AWS operations return results that are incomplete and require subsequent requests in order to attain the entire result set. Paginators are a feature of boto3 that act as an abstraction over the process of iterating over an entire result set of a truncated API operation. Cloud Control API lacks this functionality at the moment. This limitation is handled in this Collection by implementing manual client-side paginators.
-
Filtering to provide name based identification to support desired state (idempotency) logic like in amazon.aws is absent. In practice it means you cannot list all the resources and filter the result on the server-side.
-
- For example, several modules do not allow the user to set a primaryIdentifier at creation time. One possible solution would be to allow the user to set a resource name and use that name to set [Tag:Name, but as the API does not allow server-side resource filtering, we can only implement a client-side filtering using that tag information. This approach would definitely have a severe impact on performance.
-
Not all the resources support the available states. In practice this means that some resources cannot be updated or listed.
What is next?
The new amazon.cloud auto-generated Collection, besides the fact that it can be easily generated using the generator tool and has a pretty abstract set of APIs for all modules, is very straightforward to use and to re-use resources across multiple dependent resources.
We continually strive to:
- Make a Collection\'s API generated modules more usable and easier to work with.
- Increase resource supportability and cover wider use case scenarios more quickly.
- Improve the overall Collection module's performance.
What can we do to improve provisioning AWS cloud resources with Ansible? More broadly, what can we do to make API generated modules more usable and easier to work with? We'd like to hear what you think.
You can provide feedback by reporting any issue against the amazon.cloud GitHub repository.
Because the modules are auto-generated, you can contribute with GitHub Pull Requests by opening them against the amazon_cloud_code_generator tool and not the resulting Collection.
In conclusion
Although in its alpha version, the new amazon.cloud content Collection shows enormous potential for automating your deployments on AWS with Ansible and greatly increasing the chances of your cloud initiative being successful.
We hope you found this blog post helpful! But, more importantly, we hope it inspired you to try out the latest amazon.cloud Collection release and let us know what you think.