Shell Scripts to Ansible
During a recent client visit, we were asked to help migrate the
following script for deploying a centralized sudoers file to RHEL and
AIX servers. This is a common scenario which can provide some good
examples of leveraging advanced Ansible features. Additionally, we can
consider the shift in approach from a script that does a task to
describing and enforcing the state of an item idempotently.
Here is the script:
#!/bin/sh
# Desc: Distribute unified copy of /etc/sudoers
#
# $Id: $
#set -x
export ODMDIR=/etc/repos
#
# perform any cleanup actions we need to do, and then exit with the
# passed status/return code
#
clean_exit()
{
cd /
test -f "$tmpfile" && rm $tmpfile
exit $1
}
#Set variables
PROG=`basename $0`
PLAT=`uname -s|awk '{print $1}'`
HOSTNAME=`uname -n | awk -F. '{print $1}'`
HOSTPFX=$(echo $HOSTNAME |cut -c 1-2)
NFSserver="nfs-server"
NFSdir="/NFS/AIXSOFT_NFS"
MOUNTPT="/mnt.$$"
MAILTO="unix@company.com"
DSTRING=$(date +%Y%m%d%H%M)
LOGFILE="/tmp/${PROG}.dist_sudoers.${DSTRING}.log"
BKUPFILE=/etc/sudoers.${DSTRING}
SRCFILE=${MOUNTPT}/skel/sudoers-uni
MD5FILE="/.sudoers.md5"
echo "Starting ${PROG} on ${HOSTNAME}" >> ${LOGFILE} 2>&1
# Make sure we run as root
runas=`id | awk -F'(' '{print $1}' | awk -F'=' '{print $2}'`
if [ $runas -ne 0 ] ; then
echo "$PROG: you must be root to run this script." >> ${LOGFILE} 2>&1
exit 1
fi
case "$PLAT" in
SunOS)
export PINGP=" -t 7 $NFSserver "
export MOUNTP=" -F nfs -o vers=3,soft "
export PATH="/usr/sbin:/usr/bin"
echo "SunOS" >> ${LOGFILE} 2>&1
exit 0
;;
AIX)
export PINGP=" -T 7 $NFSserver 2 2"
export MOUNTP=" -o vers=3,bsy,soft "
export PATH="/usr/bin:/etc:/usr/sbin:/usr/ucb:/usr/bin/X11:/sbin:/usr/java5/jre/bin:/usr/java5/bin"
printf "Continuing on AIX...\n\n" >> ${LOGFILE} 2>&1
;;
Linux)
export PINGP=" -t 7 -c 2 $NFSserver"
export MOUNTP=" -o nfsvers=3,soft "
export PATH="/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin"
printf "Continuing on Linux...\n\n" >> ${LOGFILE} 2>&1
;;
*)
echo "Unsupported Platform." >> ${LOGFILE} 2>&1
exit 1
esac
##
## Exclude Lawson Hosts
##
if [ ${HOSTPFX} = "la" ]
then
echo "Exiting Lawson host ${HOSTNAME} with no changes." >> ${LOGFILE} 2>&1
exit 0
fi
##
## * NFS Mount Section *
##
## Check to make sure NFS host is up
printf "Current PATH is..." >> ${LOGFILE} 2>&1
echo $PATH >> $LOGFILE 2>&1
ping $PINGP >> $LOGFILE 2>&1
if [ $? -ne 0 ]; then
echo " NFS server is DOWN ... ABORTING SCRIPT ... Please check server..." >> $LOGFILE
echo "$PROG failed on $HOSTNAME ... NFS server is DOWN ... ABORTING SCRIPT ... Please check server ... " | mailx -s "$PROG Failed on $HOSTNAME" $MAILTO
exit 1
else
echo " NFS server is UP ... We will continue..." >> $LOGFILE
fi
##
## Mount NFS share to HOSTNAME. We do this using a soft mount in case it is lost during a backup
##
mkdir $MOUNTPT
mount $MOUNTP $NFSserver:${NFSdir} $MOUNTPT >> $LOGFILE 2>&1
##
## Check to make sure mount command returned 0. If it did not odds are something else is mounted on /mnt.$$
##
if [ $? -ne 0 ]; then
echo " Mount command did not work ... Please check server ... Odds are something is mounted on $MOUNTPT ..." >> $LOGFILE
echo " $PROG failed on $HOSTNAME ... Mount command did not work ... Please check server ... Odds are something is mounted on $MOUNTPT ..." | mailx -s "$PROG Failed on $HOSTNAME" $MAILTO
exit 1
else
echo " Mount command returned a good status which means $MOUNPT was free for us to use ... We will now continue ..." >> $LOGFILE
fi
##
## Now check to see if the mount worked
##
if [ ! -f ${SRCFILE} ]; then
echo " File ${SRCFILE} is missing... Maybe NFS mount did NOT WORK ... Please check server ..." >> $LOGFILE
echo " $PROG failed on $HOSTNAME ... File ${SRCFILE} is missing... Maybe NFS mount did NOT WORK ... Please check server ..." | mailx -s "$PROG Failed on $HOSTNAME" $MA
ILTO
umount -f $MOUNTPT >> $LOGFILE
rmdir $MOUNTPT >> $LOGFILE
exit 1
else
echo " NFS mount worked we are going to continue ..." >> $LOGFILE
fi
##
## * Main Section *
##
if [ ! -f ${BKUPFILE} ]
then
cp -p /etc/sudoers ${BKUPFILE}
else
echo "Backup file already exists$" >> ${LOGFILE} 2>&1
exit 1
fi
if [ -f "$SRCFILE" ]
then
echo "Copying in new sudoers file from $SRCFILE." >> ${LOGFILE} 2>&1
cp -p $SRCFILE /etc/sudoers
chmod 440 /etc/sudoers
else
echo "Source file not found" >> ${LOGFILE} 2>&1
exit 1
fi
echo >> ${LOGFILE} 2>&1
visudo -c |tee -a ${LOGFILE}
if [ $? -ne 0 ]
then
echo "sudoers syntax error on $HOSTNAME." >> ${LOGFILE} 2>&1
mailx -s "${PROG}: sudoers syntax error on $HOSTNAME" "$MAILTO" << EOF
Syntax error /etc/sudoers on $HOSTNAME.
Reverting changes
Please investigate.
EOF
echo "Reverting changes." >> ${LOGFILE} 2>&1
cp -p ${BKUPFILE} /etc/sudoers
else
#
# Update checksum file
#
grep -v '/etc/sudoers' ${MD5FILE} > ${MD5FILE}.tmp
csum /etc/sudoers >> ${MD5FILE}.tmp
mv ${MD5FILE}.tmp ${MD5FILE}
chmod 600 ${MD5FILE}
fi
echo >> ${LOGFILE} 2>&1
if [ "${HOSTPFX}" = "hd" ]
then
printf "\nAppending #includedir /etc/sudoers.d at end of file.\n" >> ${LOGFILE} 2>&1
echo "" >> /etc/sudoers
echo "## Read drop-in files from /etc/sudoers.d (the # here does not mean a comment)" >> /etc/sudoers
echo "#includedir /etc/sudoers.d" >> /etc/sudoers
fi
##
## * NFS Un-mount Section *
##
##
## Unmount /mnt.$$ directory
##
umount ${MOUNTPT} >> $LOGFILE 2>&1
if [ -d ${MOUNTPT} ]; then
rmdir ${MOUNTPT} >> $LOGFILE 2>&1
fi
##
## Make sure that /mnt.$$ got unmounted
##
if [ -f ${SRCFILE} ]; then
echo " The umount command failed to unmount ${MOUNTPT} ... We will not force the unmount ..." >> $LOGFILE
umount -f ${MOUNTPT} >> $LOGFILE 2>&1
if [ -d ${MOUNTPT} ]; then
rmdir ${MOUNTPT} >> $LOGFILE 2>&1
fi
else
echo " $MOUNTPT was unmounted ... There is no need for user intervention on $HOSTNAME ..." >> $LOGFILE
fi
#
# as always, exit cleanly
#
clean_exit 0
That's 212 lines of code; there's no versioning of the sudoers file. The
customer has an existing process that runs weekly to validate the
checksum of the file for security. Although the script references
Solaris, for this customer we did not need to migrate the Solaris
requirement.
We started with the idea of creating a role and placing the sudoers file
into Git for version control. This also removes the need for NFS mounts.
With the "validate" and "backup" parameters for the copy and
template modules, we can eliminate the need for code to backup and
restore the file. The validation is run before the file is placed in the
destination and, if failed, the module errors out.
We'll need tasks, templates and vars for the role. Here's the file
layout:
├── README.md
├── roles
│ └── sudoers
│ ├── tasks
│ │ └── main.yml
│ ├── templates
│ │ └── sudoers.j2
│ └── vars
│ └── main.yml
└── sudoers.yml
The role playbook, sudoers.yml, is simple:
---
##
# Role playbook
##
- hosts: all
roles:
- sudoers
...
Role variables are located in the vars/main.yml file. I've set
variables for the checksum file, and include/exclude variables that will
be used to create the logic that skips "Lawson" hosts and only adds the
sudoers.d include to "hd" hosts.
Below is what is in the vars/main.yml file:
---
MD5FILE: /root/.sudoer.md5
EXCLUDE: la
INCLUDE: hd
...
If we use the copy and lineinfile modules, the role will not be
idempotent. Copy will deploy the base file, and lineinfile will have to
reinsert the includes on every run. As this role will be scheduled in
Ansible Tower, idempotence is a requirement. We'll convert the file to a
jinja2 template.
In the first line, we add the following to manage whitespace and indentations:
#jinja2: lstrip_blocks: True, trim_blocks: True
Note that newer versions of the template module include parameters for
trim_blocks (added in Ansible 2.4).
Here is the code to insert the include line at the end of the file:
{% if ansible_hostname[0:2] == INCLUDE %}
#includedir /etc/sudoers.d
{% endif %}
We use a conditional ( {% if %}, {% endif %} ) to replace the shell
that inserts the line for hosts where "hd" is in the first two
characters of the hostname. We leverage Ansible facts and the filter
[0:2] to parse the hostname.
Now for the tasks. First, set a fact to parse the hostname. We will use
the "parhost" fact in conditionals.
---
##
# Parse hostnames to grab 1st 2 characters
##
- name: "Parse hostname's 1st 2 characters"
set_fact: parhost={{ ansible_hostname[0:2] }}
Next, I noticed that csum doesn't exist on a stock RHEL server. In
case it's needed, we can use another fact to conditionally set the name
of the checksum binary. Note that further coding may be needed if that
differs between AIX, Solaris and Linux. As the customer was not
concerned with the Solaris hosts, I skipped that development.
We'll also deal with the difference in root's groups between AIX and RHEL.
##
# Conditionally set name of checksum binary
##
- name: "set checksum binary"
set_fact:
csbin: "{{ 'cksum' if (ansible_distribution == 'RedHat') else 'csum' }}"
##
# Conditionally set name of root group
##
- name: "set system group"
set_fact:
sysgroup: "{{ 'root' if (ansible_distribution == 'RedHat') else 'sys' }}"
Blocks will allow us to provide a conditional around the tasks. We'll
use a conditional at the end of the block to exclude the "la"
hosts.
##
# Enclose in block so we can use parhost to exclude hosts
##
- block:
The template module validates and deploys the file. We register the
result so we can determine if there was a change in this task. Using the
validate parameter of the module ensures the new sudoers file is valid
before putting it in place.
##
# Validate will prevent bad files, no need to revert
# Jinja2 template will add include line
##
- name: Ensure sudoers file
template:
src: sudoers.j2
dest: /etc/sudoers
owner: root
group: "{{ sysgroup }}"
mode: 0440
backup: yes
validate: /usr/sbin/visudo -cf %s
register: sudochg
If a new template was deployed, we run shell to generate the checksum file.
The conditional updates the checksum file when the sudoers template is deployed, or if the checksum file is missing.
As the existing process also monitors other files, we use the shell code provided in the original script:
- name: sudoers checksum
shell: "grep -v '/etc/sudoers' {{ MD5FILE }} > {{ MD5FILE }}.tmp ; {{ csbin }} /etc/sudoers >> {{ MD5FILE }} ; mv {{ MD5FILE }}.tmp {{ MD5FILE }}"
when: sudochg.changed or MD5STAT.exists == false
The file module enforces the permissions:
- name: Ensure MD5FILE permissions
file:
path: "{{ MD5FILE }}"
owner: root
group: "{{ sysgroup }}"
mode: 0600
state: file
Since the backup parameter does not provide any options for cleanup of older backups, we'll add some code to handle that for us.
This also demonstrates leveraging the "register" and "stdout_lines" features.
##
# List and clean up backup files. Retain 3 copies.
##
- name: List /etc/sudoers.*~ files
shell: "ls -t /etc/sudoers*~ |tail -n +4"
register: LIST_SUDOERS
changed_when: false
- name: Cleanup /etc/sudoers.*~ files
file:
path: "{{ item }}"
state: absent
loop: "{{ LIST_SUDOERS.stdout_lines }}"
when: LIST_SUDOERS.stdout_lines != ""
Closing the block:
##
# This conditional restricts what hosts this block runs on
##
when: parhost != EXCLUDE
...
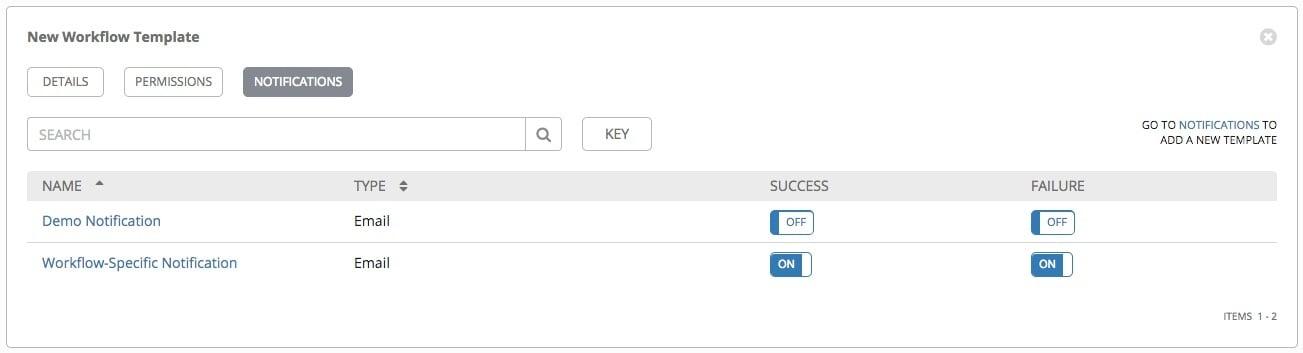
The intended use here is to run this role in Ansible Tower. Ansible
Tower notifications can be configured for job failure via email, Slack
or other methods. This role runs in Ansible, Ansible Engine or Ansible
Tower.
We've condensed the script and created a fully idempotent role that can
enforce the desired state of the sudoers file. Use of SCM provides
versioning, better change management and accountability. CI/CD with
Jenkins or other tools can provide automated testing of the Ansible code
for future changes. The Auditor role in Ansible Tower can oversee and
maintain the compliance requirements of organizations.
We could remove the process around the checksum, but the customer will
have to have conversations with their Security team first. If desired,
the sudoers template can be protected with Ansible Vault. Finally, use
of groups could replace the logic around the includes and excludes.
You can find the role on GitHub.
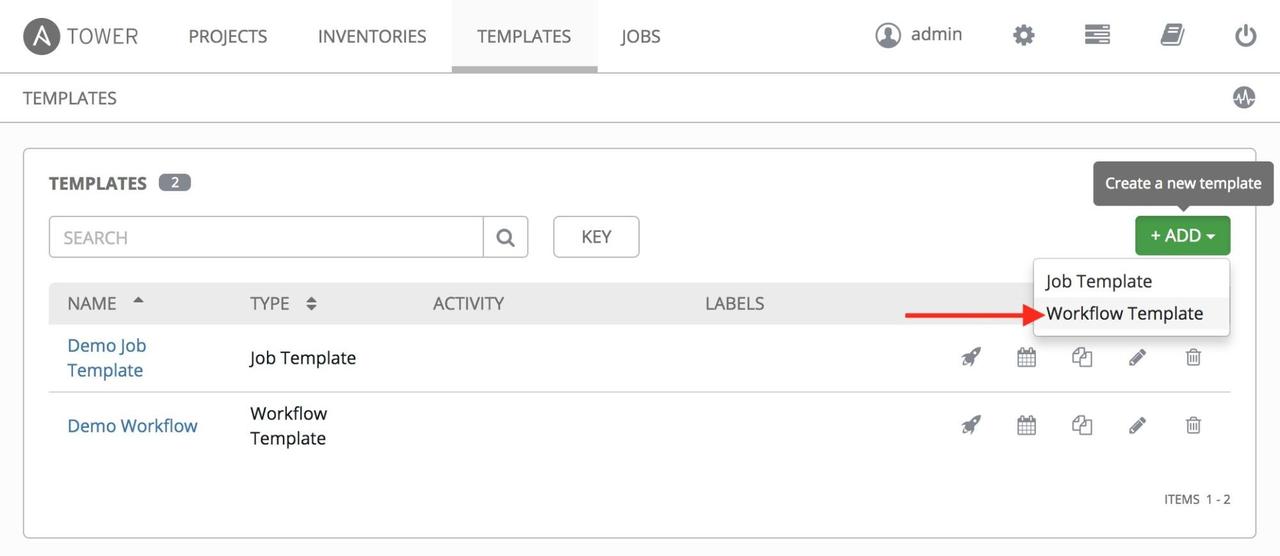
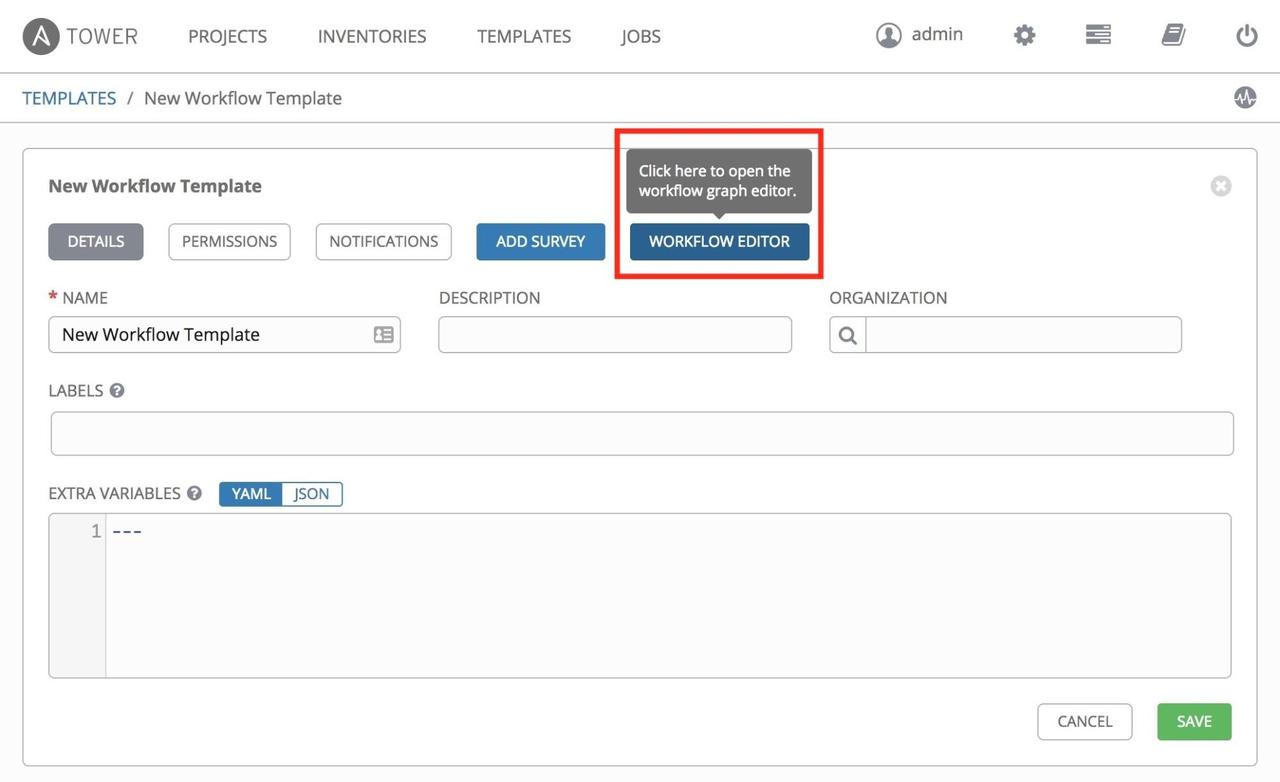
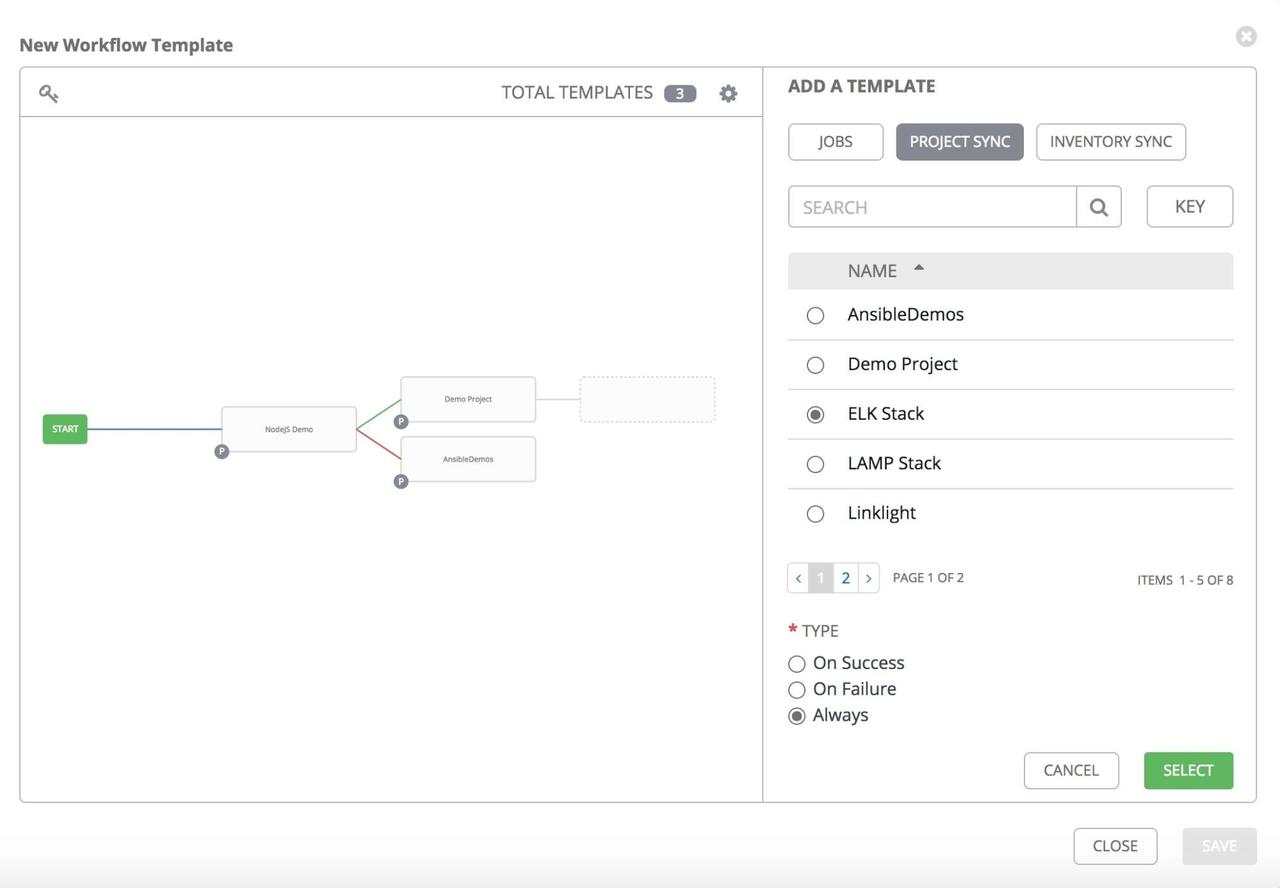

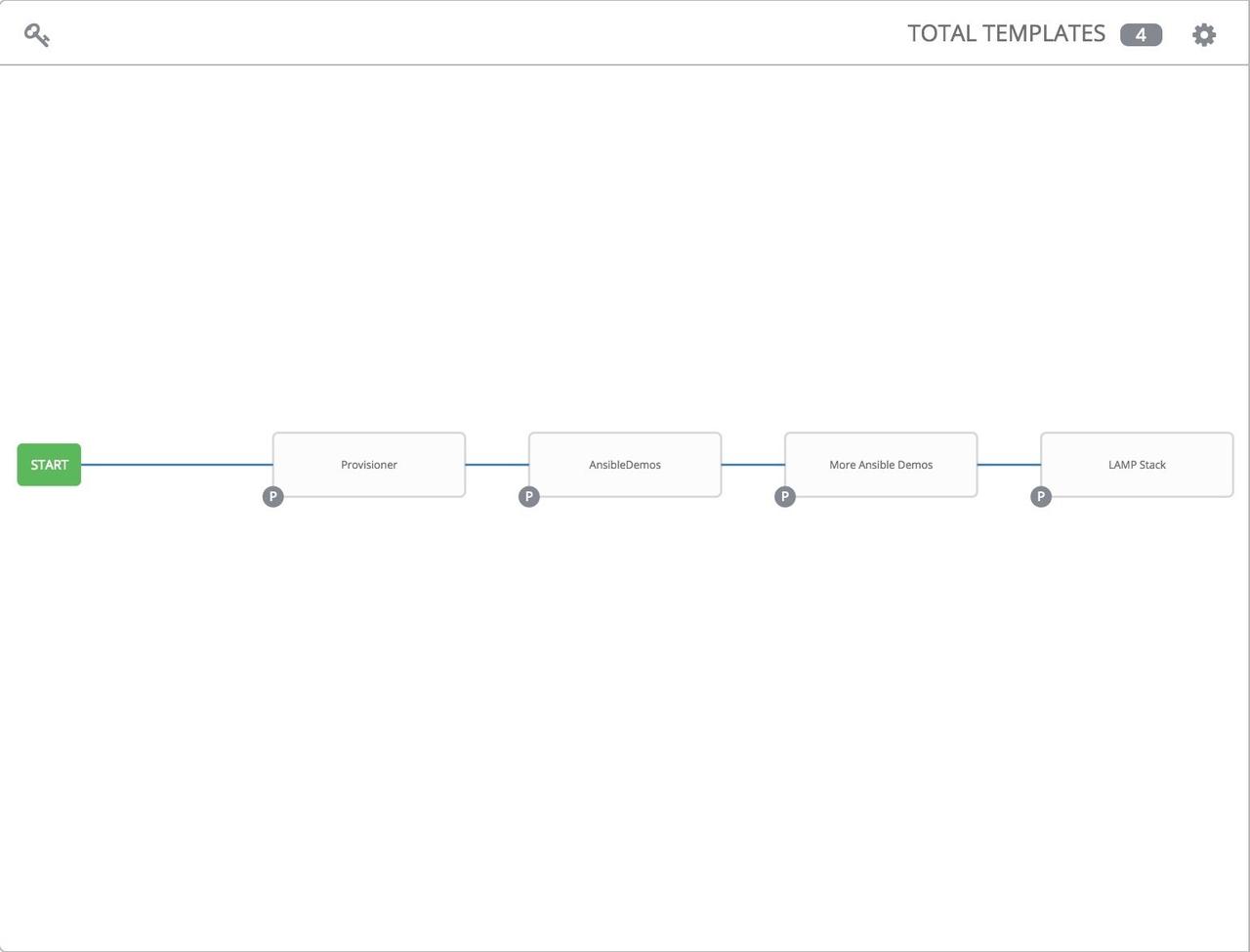
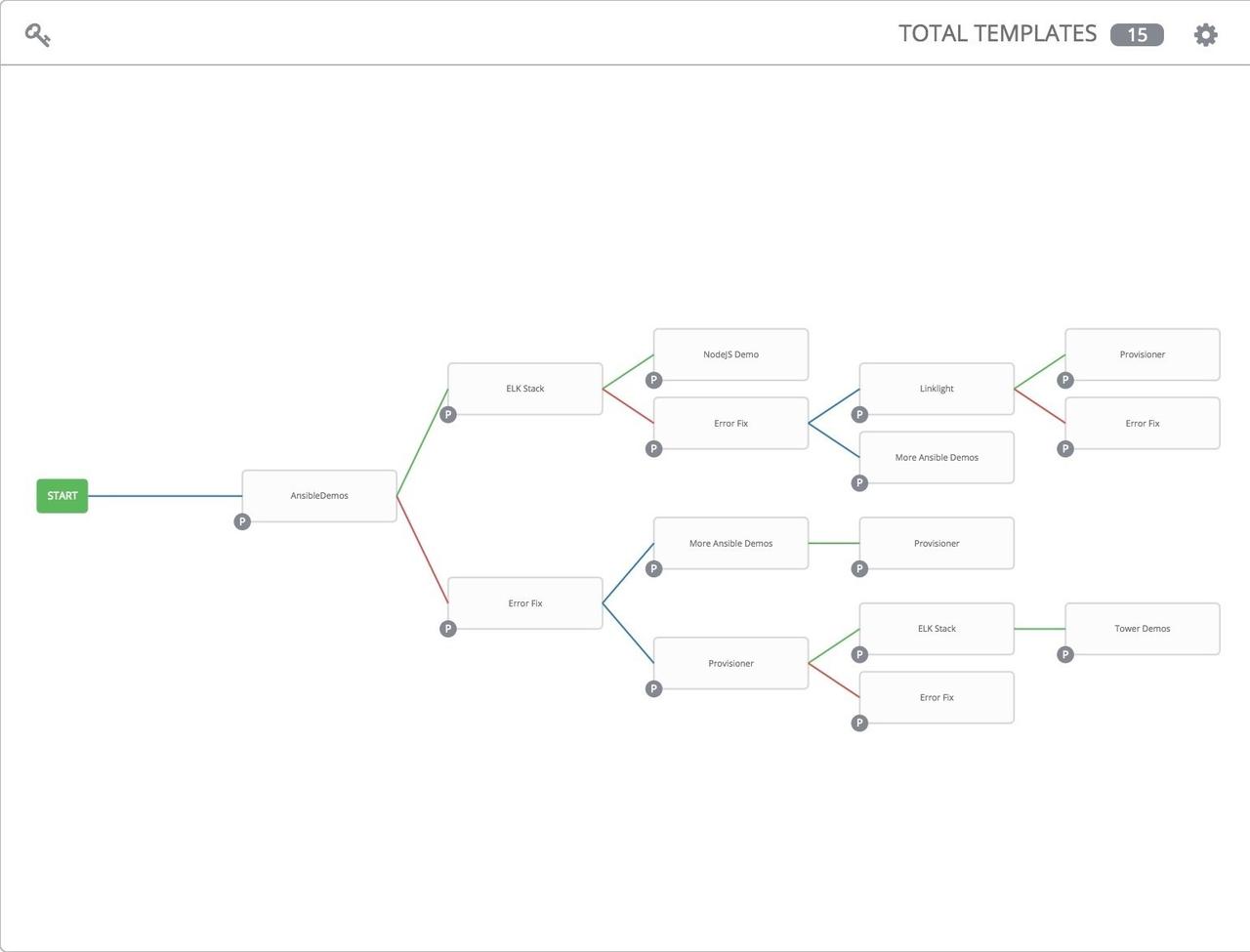
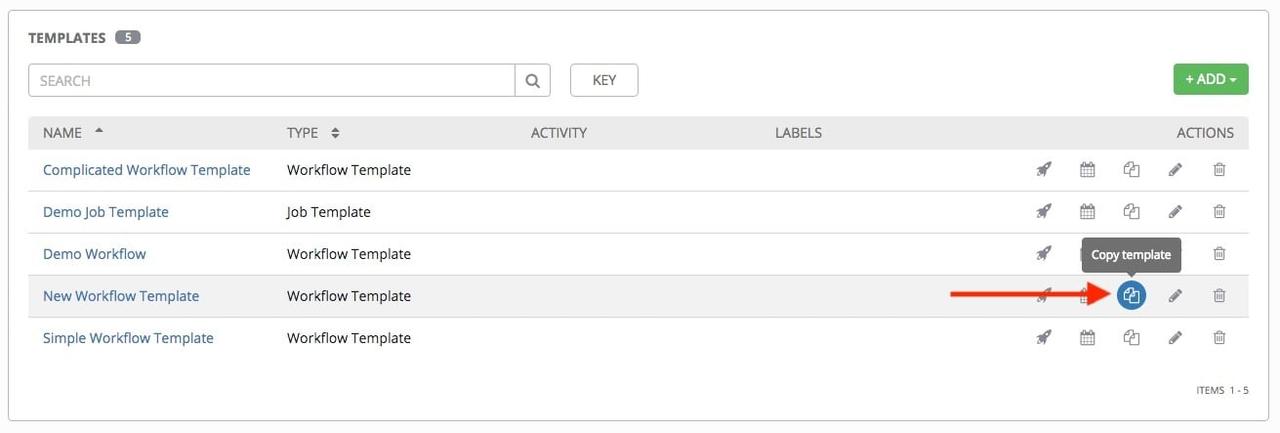
 If you have a workflow template created that works very well for you and
you'd like to copy it, click on the button highlighted below:
If you have a workflow template created that works very well for you and
you'd like to copy it, click on the button highlighted below: