Using Infoblox as a dynamic inventory in Red Hat Ansible Tower
Using Infoblox as a dynamic inventory in Red Hat Ansible Tower
Do you still use spreadsheets to keep track of all your device inventory? Do you have Infoblox Appliances deployed in your infrastructure? Do you want to start automating without the burden of maintaining a static register of devices? If you answered yes to any of these questions, this blog is for you.
Operations teams often struggle to keep their Configuration Management Databases (CMDBs) up-to-date, primarily because they were not involved in the specification process to share what pieces of information are relevant to them, or even if they were, once it is put in place:
Teams are not allowed to change any of their Configuration Items (CI) because they have only read-only access!
The reality is that a lot of the time when we talk about a CMDB, we are talking about tables in a database without any version control mechanism, therefore only read access is provided to end users.
The impact is that in order to perform lifecycle management (Create/Update/Decommission) of their configuration items, teams must go through a fastidious and manual process until they give up changing CIs (Configuration Items) in the CMDB and just leave everything as it is. What happens next? Different teams start to rely on their own CMDBs (A.K.A spreadsheets), to track subnets, IP allocations, DNS records, Zones, Views, etc. What's the end result? End users request their machines and still need to wait at least a week before someone from the NetOps team consults their own CMDB (yes, the spreadsheet) to provide them DNS records and IP addresses.
Dynamic Inventory
Dynamic Inventory is one of the most powerful features in Red Hat Ansible Tower. Dynamic Inventory allows Ansible to query external systems and use the response data to construct its inventory. Red Hat Ansible Tower provides some out-of-the-box integrations through dynamic inventory scripts, and also allows users to extend these capabilities by providing their own custom dynamic inventory script.
Red Hat Ansible Tower and Infoblox
Let's take a look at the steps required to configure a custom dynamic inventory script to query Infoblox and rely on it as our inventory source of truth.
Install infoblox-client
First we need to install the infoblox-client python library in Red Hat Ansible Tower's venv of each node of the cluster, and the configuration file required by the infoblox inventory script:
# source /var/lib/awx/venv/awx/bin/activate # pip install infoblox-client
NOTE: You could also create a playbook to do this, using the Ansible pip_module.
Create the infoblox configuration file in /etc/ansible/infoblox.yaml:
--- filters: extattrs: {} view: null
NOTE: Follow this Ansible GitHub Issue where I suggest taking configuration items from an environment variable or a file for added flexibility.
Credential Type
After the installation in the previous step completes successfully in all the nodes of the cluster, we need to specify in Ansible Tower the credential and hostname to establish communication with Infoblox Appliances. As of today we don't have any specific Ansible Tower Credential for Infoblox, so let's create a custom credential type. We can then provide the information required to communicate with Infoblox, have the password protected by Ansible Tower and RBAC (Role-Based Access Control).
As Administrator, go to Credential Types in the left menu.
Create a new credential type: INFOBLOX_INVENTORY (Green + sign)

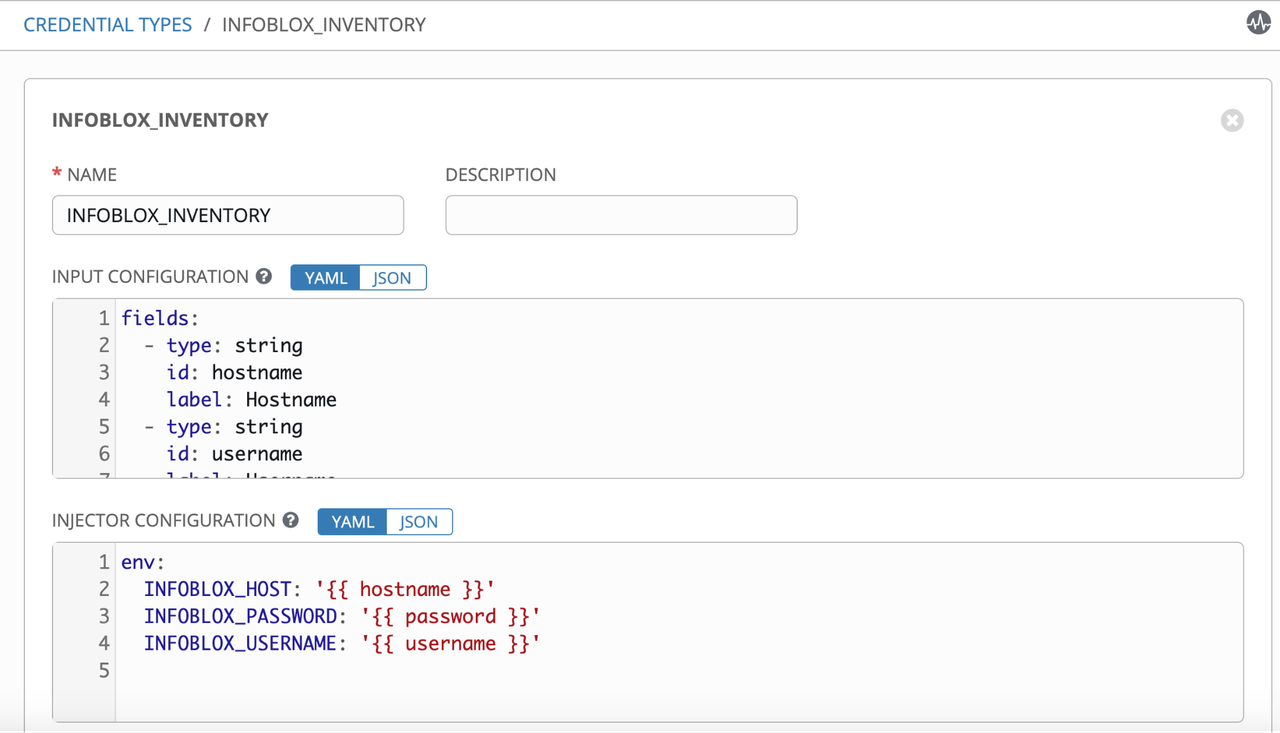
Define the inputs required in the INPUT CONFIGURATION field:
fields: - type: string id: hostname label: Hostname - type: string id: username label: Username - secret: true type: string id: password label: Password required: - username - password
Define the injection of inputs as environment variables in INJECTOR CONFIGURATION field:
env: INFOBLOX_HOST: '{{ hostname }}' INFOBLOX_PASSWORD: '{{ password }}' INFOBLOX_USERNAME: '{{ username }}'
Credential
After the creation of the credential type INFOBLOX_INVENTORY in Ansible Tower, we can use it to create a new credential, specifying the information to communicate with the Infoblox Appliance.
Create a credential to communicate with Infoblox Appliance:
infoblox-ip.ip.ip.ip
NOTE: In the example, the name includes the IP or FQDN, so we can know what appliance this particular credential refers to.
Inventory Script
Creation of custom inventory script to query Infoblox Appliances and parse the output to the format expected by Ansible inventory.
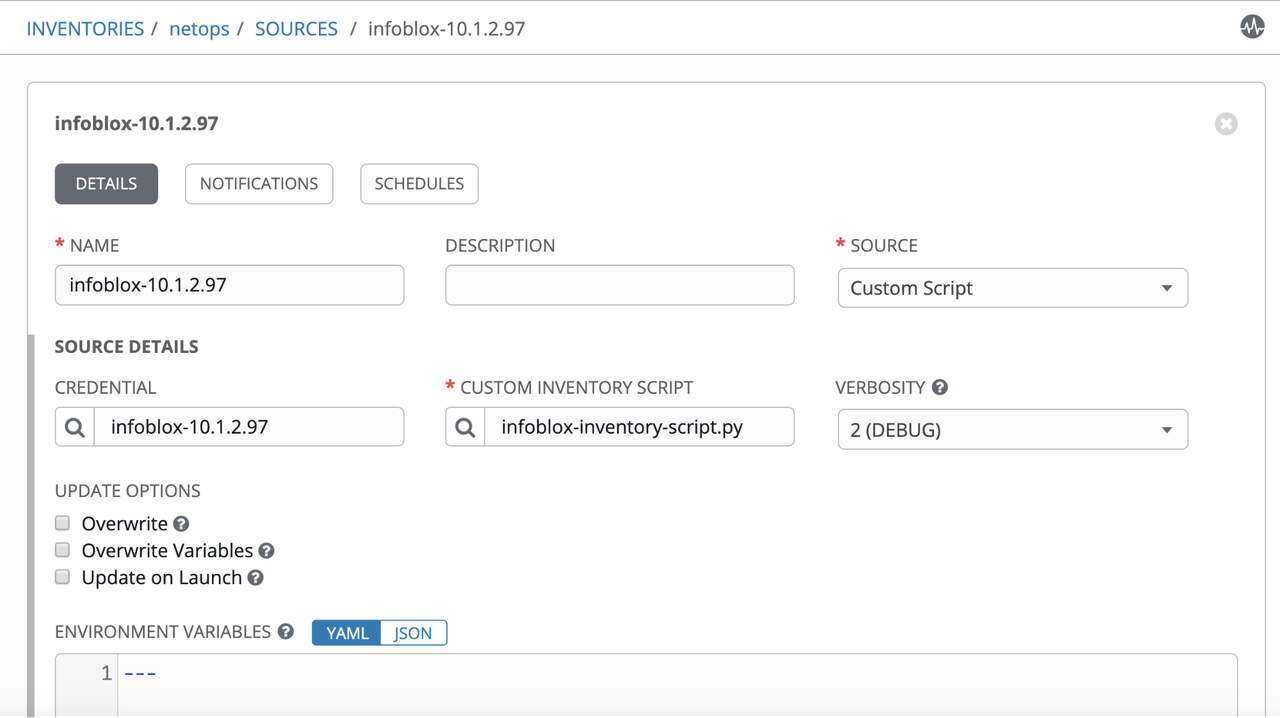
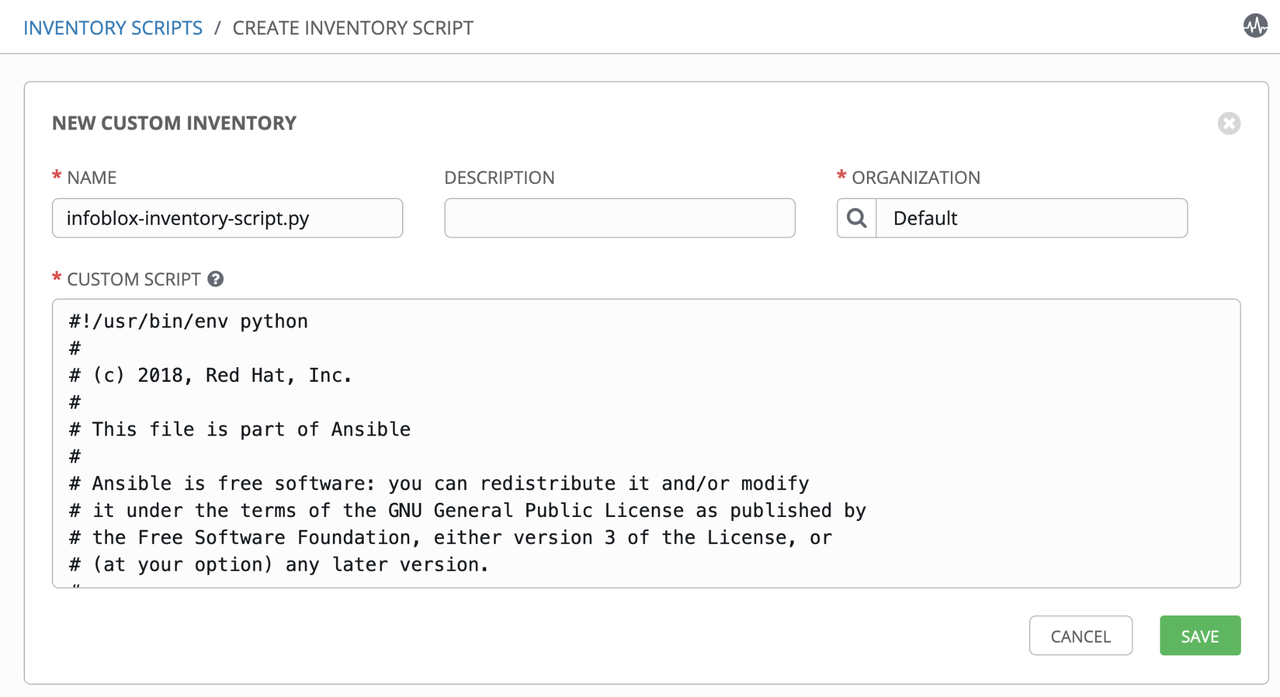
Create a new custom inventory script: _infoblox-inventory-script.py
Get the infoblox.py from Ansible's GitHub and paste into the CUSTOM SCRIPT field:
Inventory Source
Creation of inventory with the infoblox dynamic script as dynamic source and sync to populate our inventory with entries returned by Infoblox Appliance.
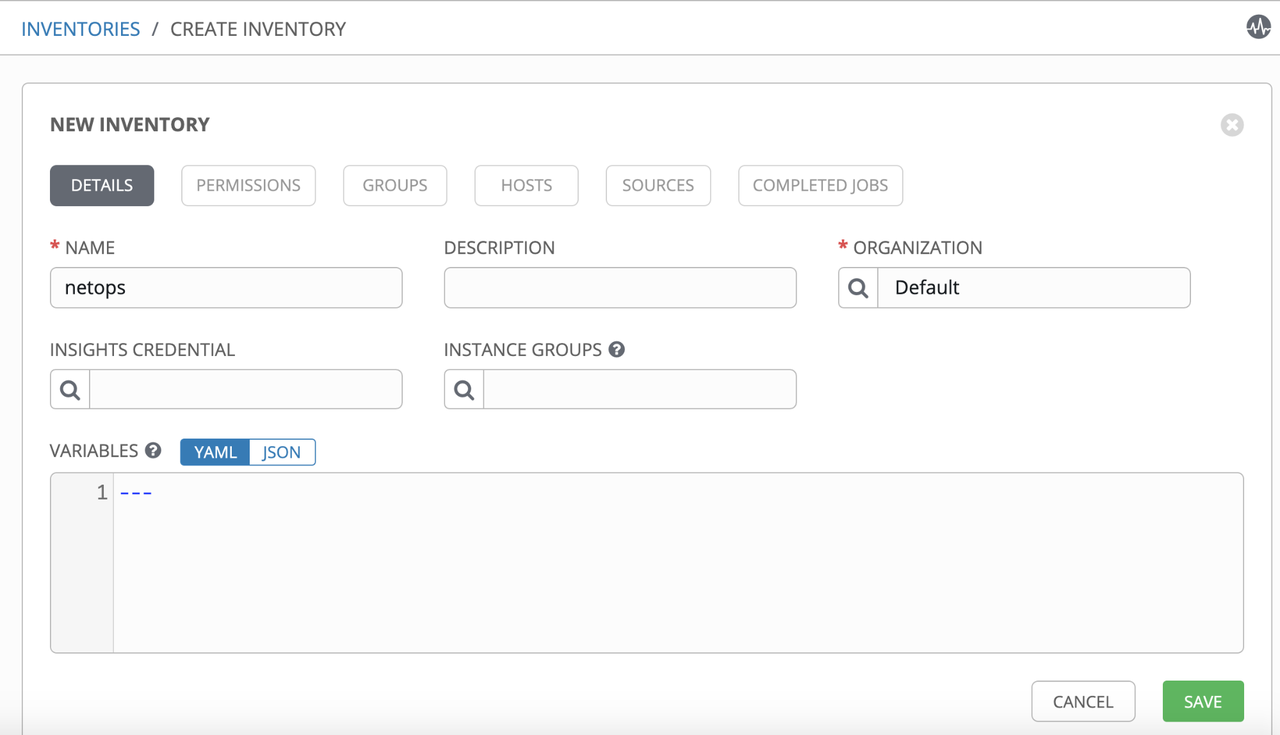
Go to Inventories and create a new Inventory: netops
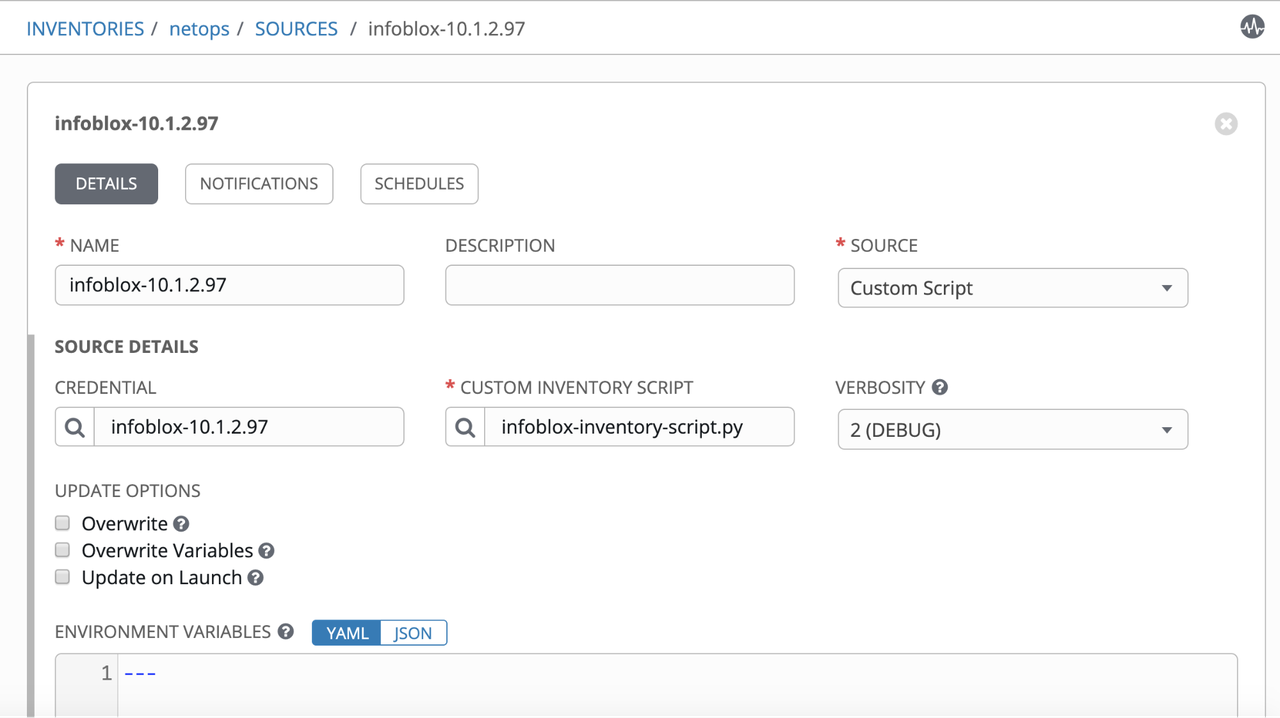
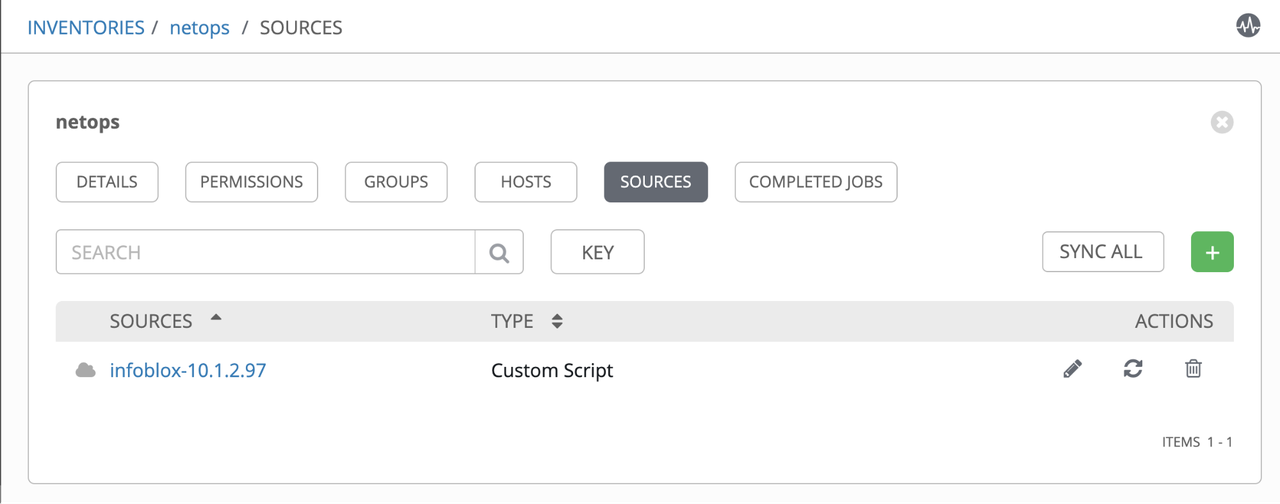
Add Source referring to the infoblox-dynamic-script.py:
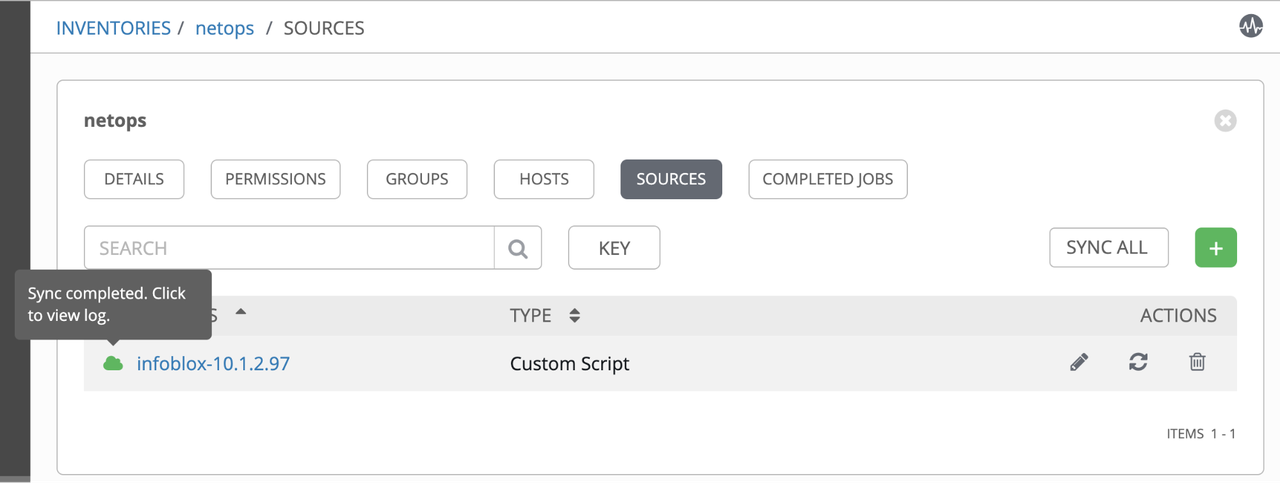
Inventory Entries
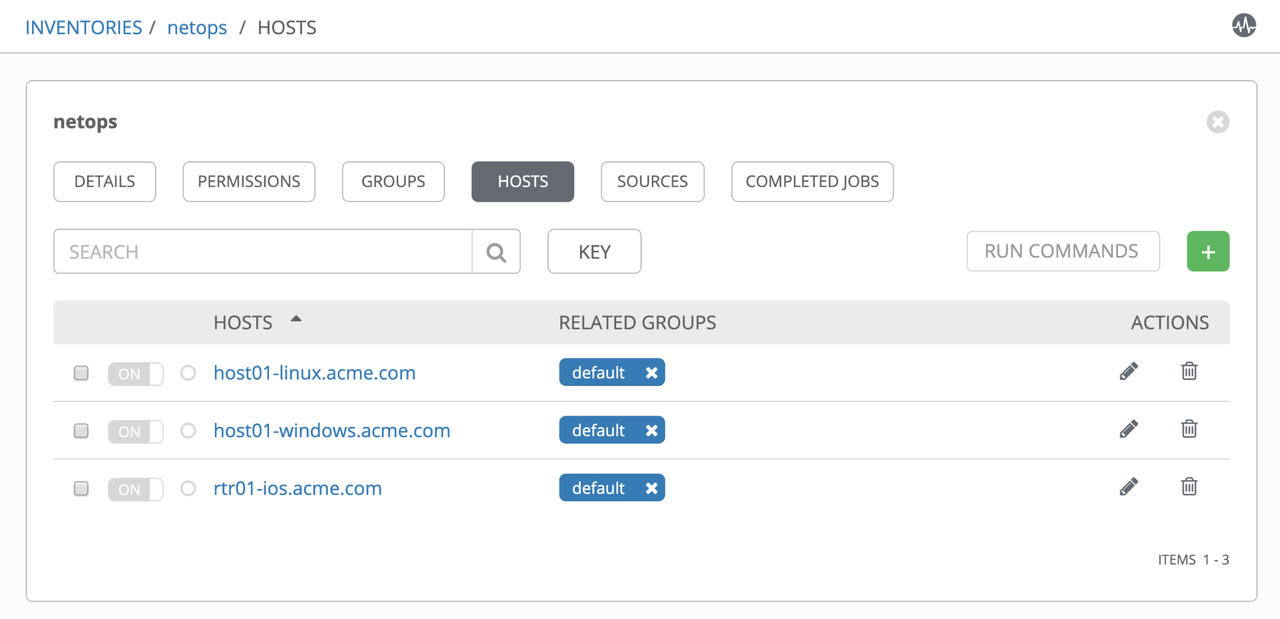
Verification if the hosts, groups and variables are being populated correctly in the inventory, based on existing entries in Infoblox Appliance:
Check host entries in inventory: netops -> hosts
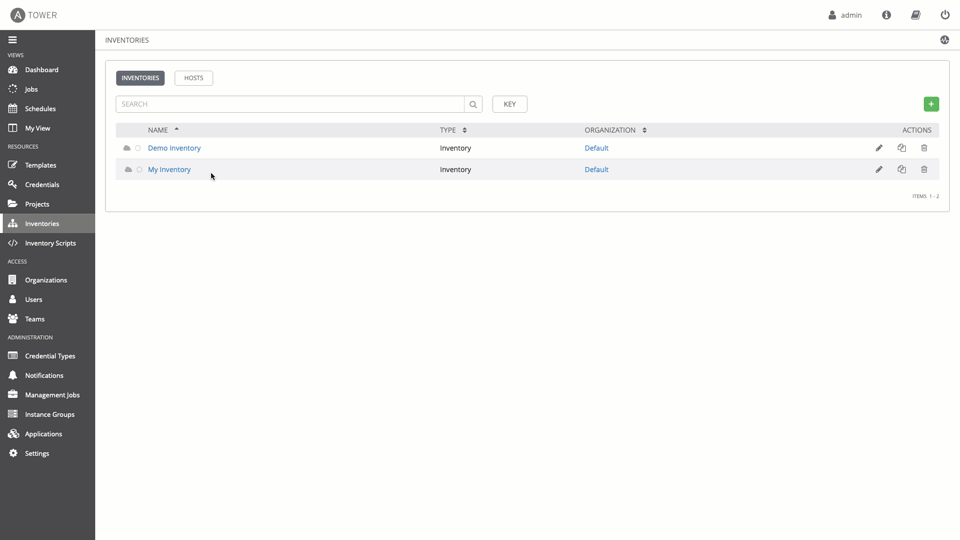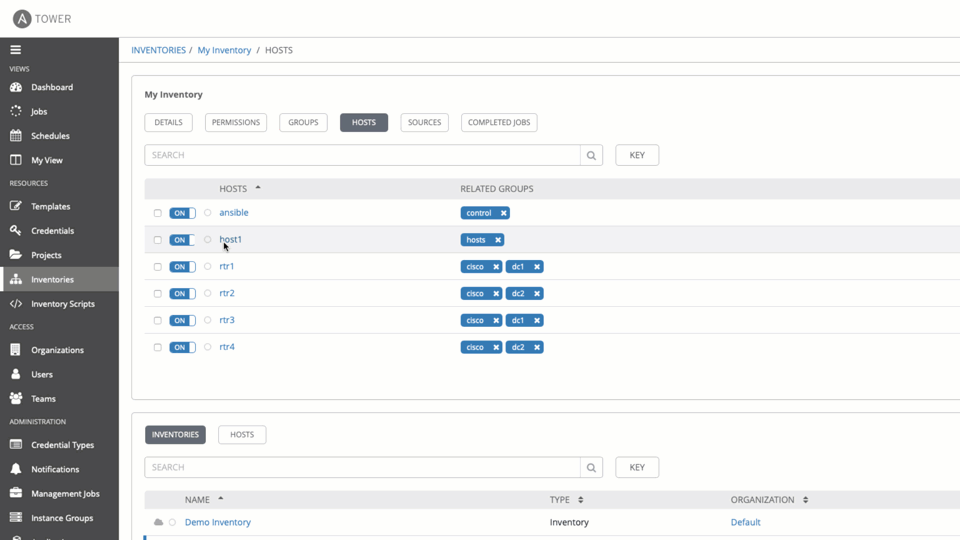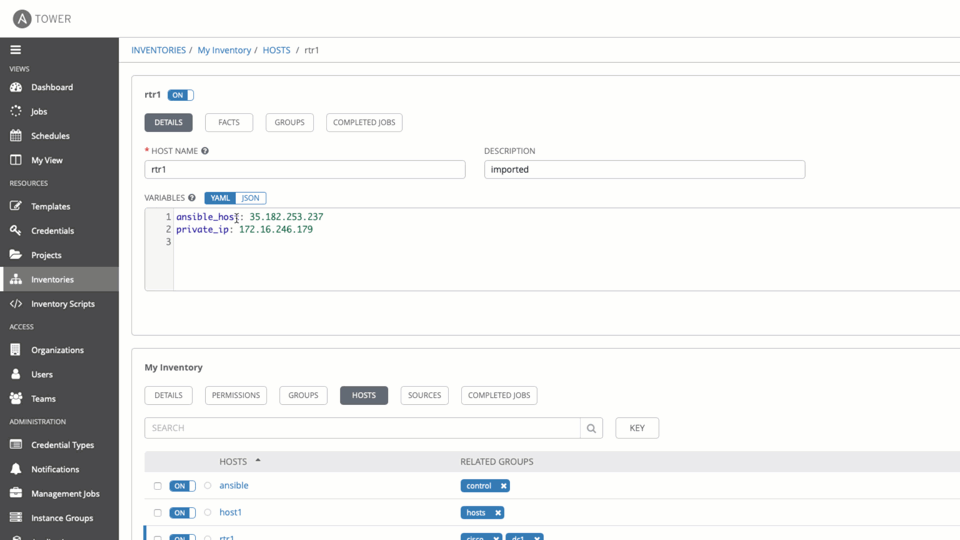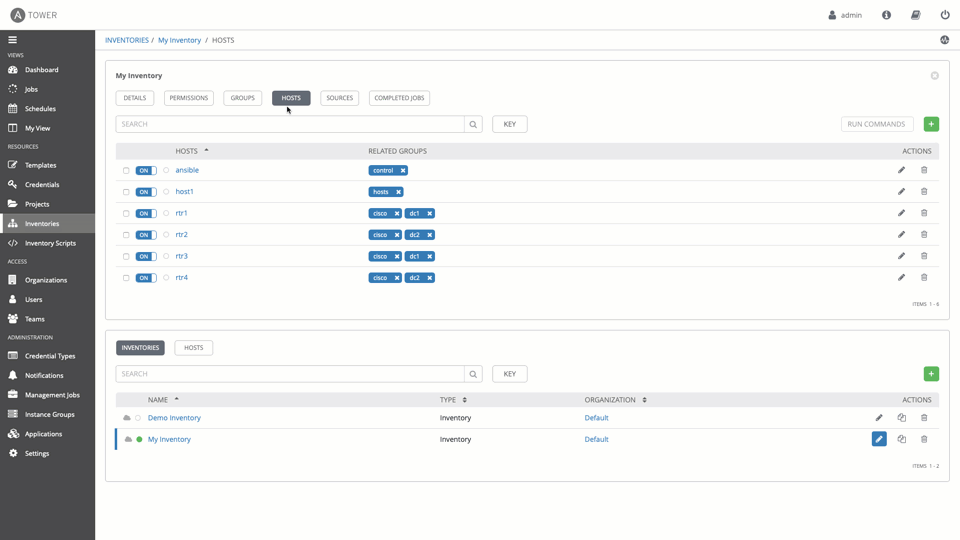
Check variables associate to a host entry: netops -> hosts -> rtr01.acme.com
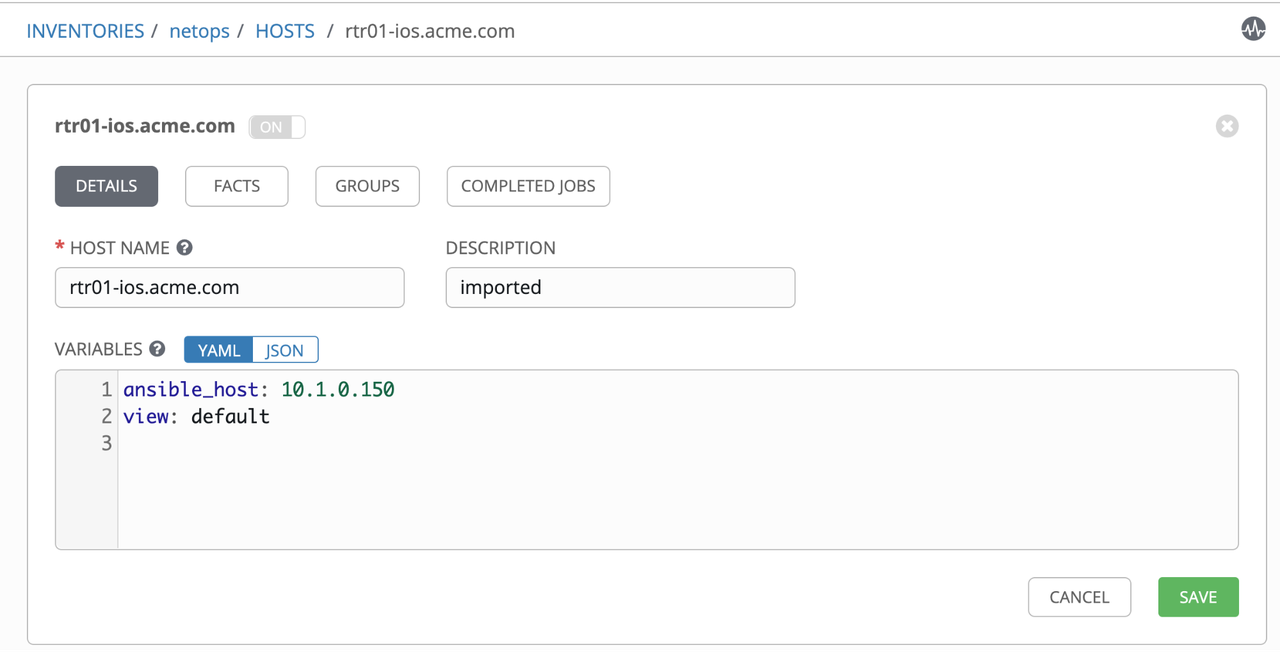
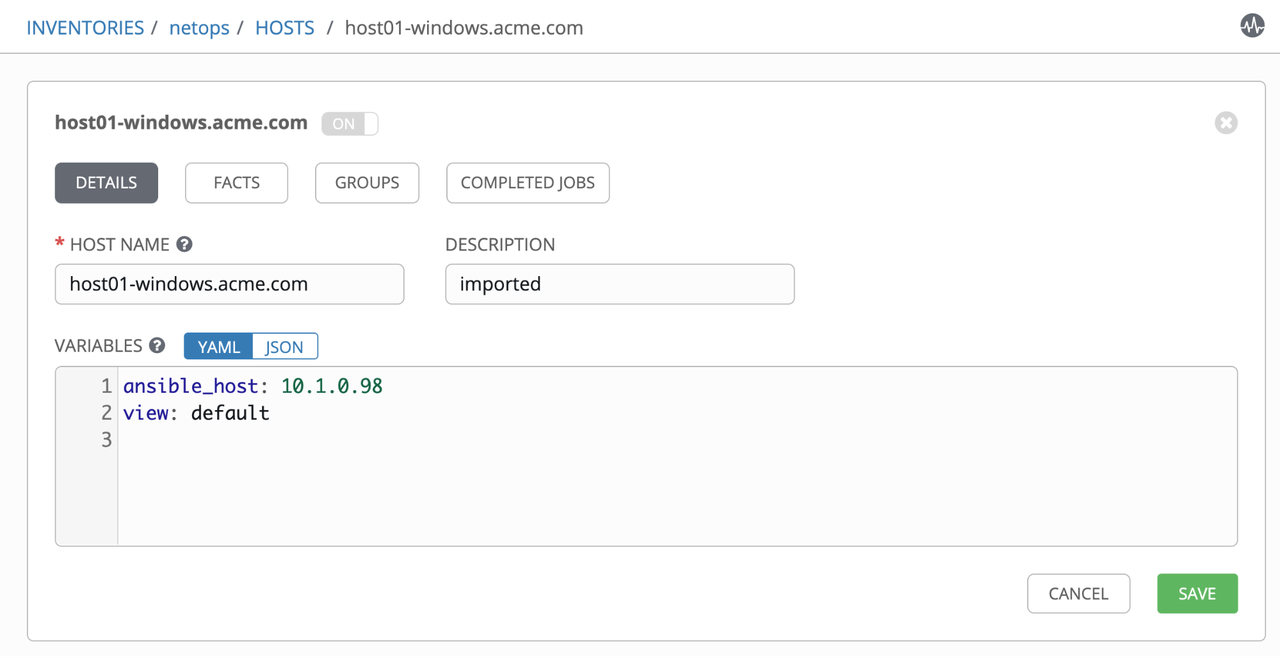
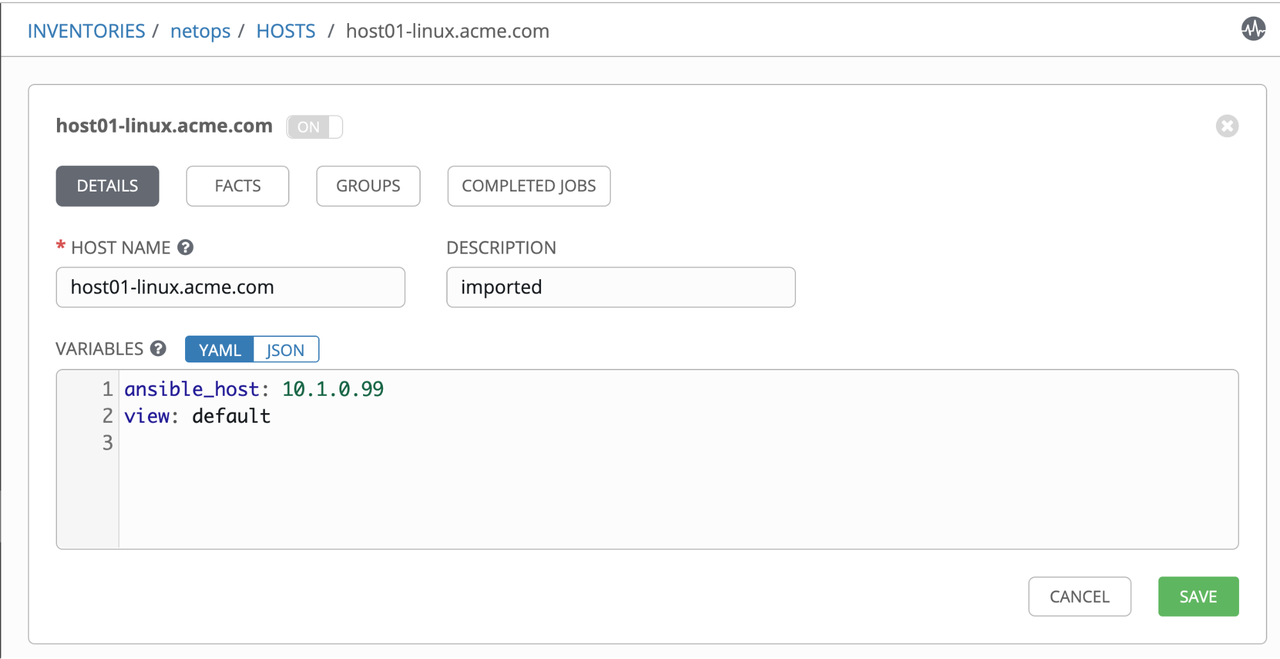
At this point we have servers and routers in our dynamic inventory, therefore from now on we can execute any Ansible Playbooks against them. In the next section we'll cover how the configurations looks like in the infoblox side.
Infoblox
At this point you may be wondering: How are these variables in Ansible Tower's Inventory specified in my Infoblox Appliance? The answer is that we are using Extensible Attributes in Infoblox to fulfill ansible_* variables, so they are automatically populated in Ansible Tower's inventory. Follow below some screenshots taken from Infoblox's WEBUI:
Extensible Attributes Configuration in Infoblox, for the variable "ansible_host":
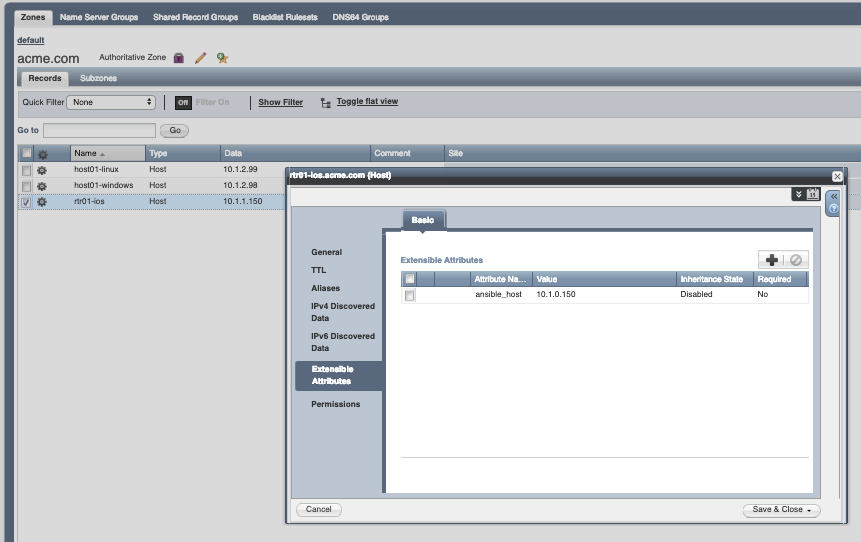
Why are we using Extensible Attributes?
The answer is simple. It is common to have entries in the DNS that refers to the production interface of the server or the service being provided, meanwhile the management access is only available via a dedicated out-of-band management interface. The ansible_host extra attribute defines that for this particular entry, Ansible shall use its value to establish communication with the server, via the management interface.
Additionally, we could rely on Extensible Attributes variable to specify if an entry is managed by Ansible Tower or not (Ex: ansible_managed: true/false), and update our "Dynamic Inventory Configuration File" accordingly, to use this particular attribute as a filter. The result is that Ansible Tower's inventory will only populate with entries that we want to automate (ansible_managed: true).