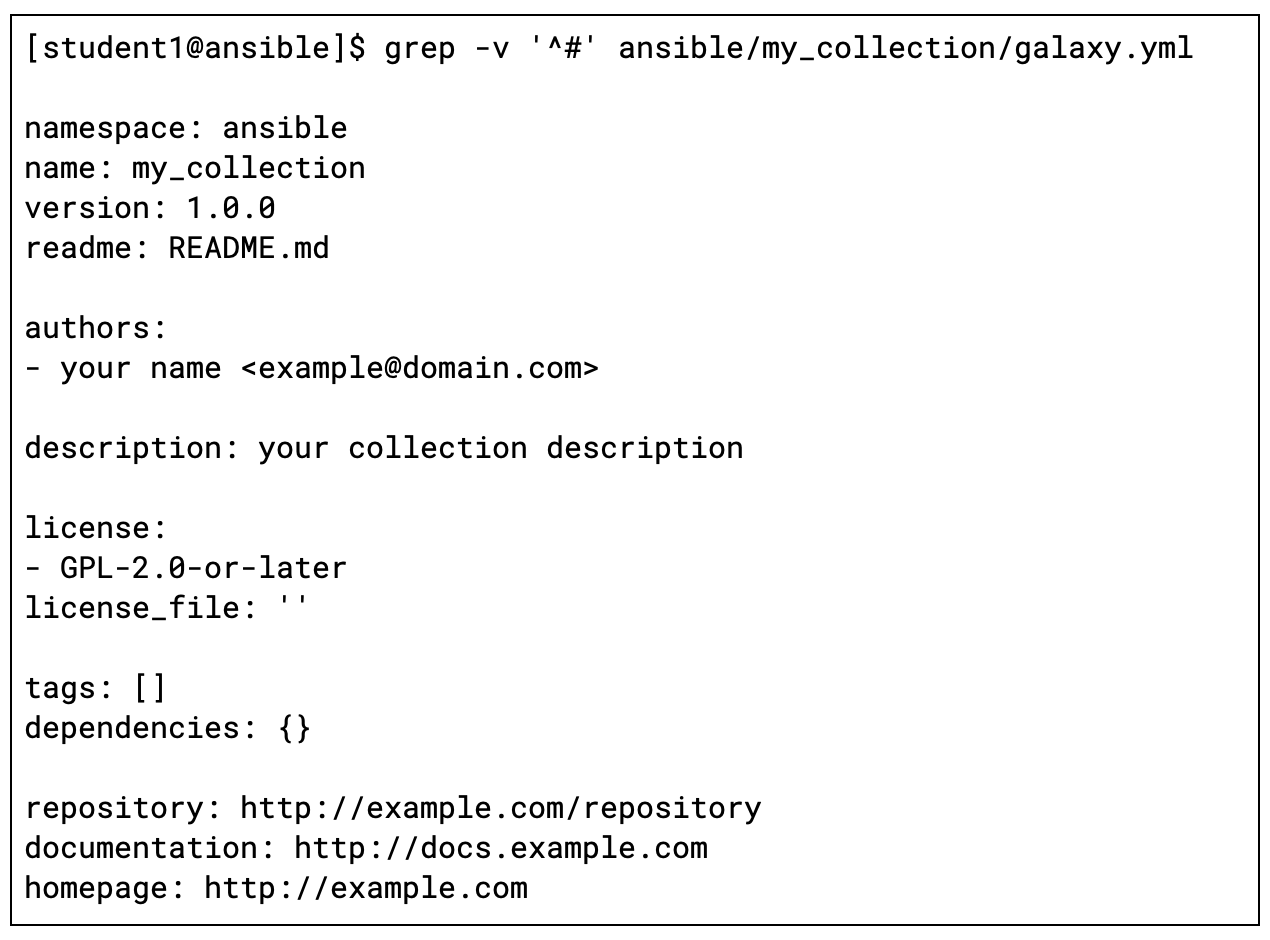
Kubernetes Operators with Ansible Deep Dive, Part 2
In part 1 of this series, we looked at operators overall, and what they do in
OpenShift/Kubernetes. We peeked at the Operator SDK, and why you'd want
to use an Ansible Operator rather than other kinds of operators provided
by the SDK. We also explored how Ansible Operators are structured and
the relevant files created by the Operator SDK when building Kubernetes
Operators with Ansible.
In this the second part of this deep dive series, we'll:
- Take a look at creating an OpenShift Project and deploying a Galera Operator.
- Next we'll check the MySQL cluster, then setup and test a Galera cluster.
- Then we'll test scaling down, disaster recovery, and demonstrate cleaning up.
Creating the project and deploying the operator
We start by creating a new project in OpenShift, which we'll simply call test:
$ oc new-project test --display-name="Testing Ansible Operator"
Now using project "test" on server "https://ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com:8443"
We won't delve too much into this role, however the basic operation is:
- Use
set_fact to generate variables using the k8s lookup plugin or other variables defined in defaults/main.yml.
- Determine if any corrective action needs to be taken based on the above variables.
For example, one variable determines how many Galera node pods are currently running.
This is compared against the variable defined on the
CustomResource.
If they differ, the role will add or remove pods as needed.
To begin the deployment, we have a simple script, which builds the operator image and pushes it to the OpenShift registry for
the test project:
$ cat ./create_operator.sh
#!/bin/bash
docker build -t docker-registry-default.router.default.svc.cluster.local/test/galera-ansible-operator:latest .
docker push docker-registry-default.router.default.svc.cluster.local/test/galera-ansible-operator:latest
kubectl create -f deploy/operator.yaml
kubectl create -f deploy/cr.yaml
Before we run this script, we need to first deploy the RBAC rules and
custom resource definition for our Galera example:
$ oc create -f deploy/rbac.yaml
clusterrole "galera-ansible-operator" created
clusterrolebinding "default-account-app-operator" created
$ oc create -f deploy/crd.yaml
customresourcedefinition "galeraservices.galera.database.coreos.com" created
Now, we run the script (after using the login command to allow docker to
connect to the OpenShift registry we created):
$ docker login -p $(oc whoami -t) -u unused docker-registry-default.router.default.svc.cluster.local
Login Succeeded
$ ./create_operator.sh
Sending build context to Docker daemon 490 kB
...
deployment.apps/galera-ansible-operator created
galeraservice "galera-example" created
In short order, we will see the galera-ansible-operator pod start up,
followed by a single pod named galera-node-0001 and a LoadBalancer
service which provides our ingress to our Galera cluster:
$ oc get all
NAME DOCKER REPO TAGS UPDATED
is/galera-ansible-operator docker-registry-default.router...:5000/test/galera-ansible-operator latest 3 hours ago
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/galera-ansible-operator 1 1 1 1 4m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/galera-external-loadbalancer 172.30.251.195 172.29.17.210,172.29.17.210 33066:30072/TCP 1m
svc/glusterfs-dynamic-galera-node-0001-mysql-data 172.30.49.250 <none> 1/TCP 1m
NAME DESIRED CURRENT READY AGE
rs/galera-ansible-operator-bc6cd548 1 1 1 4m
NAME READY STATUS RESTARTS AGE
po/galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 4m
po/galera-node-0001 1/1 Running 0 1m
Verifying the MySQL cluster, initial setup and testing
We can use the describe function to see the status of our custom
resource, specifically the size we specified:
$ kubectl describe -f deploy/cr.yaml |grep -i size
Galera _ Cluster _ Size: 1
Now that we have a MySQL cluster, let's test it using
sysbench.
As mentioned above, we have a system from which to do the testing so we
can avoid internet round trips. But first, we'll need some info. We
need to know the forwarded port we can connect to through the load
balancing service created as part of the operator deployment:
Next, we need to know the IP of the master. We can get this with oc describe:
$ oc describe node ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com| grep ^Addresses
Addresses: 10.0.0.46,ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com
So for this test, we'll be connecting to the IP 10.0.0.46 on port
XXXXX. The port value 33066 was specified in the spec above, and is the
port which will receive the forwarded traffic. We'll export those to
make it a little easier to re-use our test commands.
From the test server:
$ export MYSQL_IP=10.0.0.46
$ export MYSQL_PORT=XXXXX
Before running sysbench, we need to create the database it expects
(future versions of the Galera operator will be able to do this
automatically):
$ mysql -h $MYSQL_IP --port=$MYSQL_PORT -u root -e 'create database sbtest;'
Next, we'll prepare the test by running sysbench using the OLTP
read-only test with a table of 1 million rows:
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all --table-size=1000000 /usr/share/sysbench/oltp_read_only.lua prepare
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Initializing worker threads...
Creating table 'sbtest1'...
Inserting 1000000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'
...
Note that we use 150 threads here, as a single MySQL/MariaDB instance
defaults to this size for its maximum connections allowed.
So now that everything's ready, lets run our first test with sysbench:
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 174776
write: 0
other: 24968
total: 199744
transactions: 12484 (1239.55 per sec.)
queries: 199744 (19832.77 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0700s
total number of events: 12484
Latency (ms):
min: 3.82
avg: 120.66
max: 1028.51
95th percentile: 292.60
sum: 1506263.71
Threads fairness:
events (avg/stddev): 83.2267/42.84
execution time (avg/stddev): 10.0418/0.02
This was just one run, but re-running a few times produces similar
results. So our one-node cluster can process about 20K queries/second.
But a cluster with only one member isn't very useful - so lets scale it
up. We do this by editing the custom resource we defined earlier and
changing the galera_cluster_size variable.
For now, we'll spin up to a three-node cluster:
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
Next, we can verify OpenShift sees this new value:
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 3
And in short order, we see the Ansible operator receive an event
signalling the change and start working to update the cluster:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 30m
galera-node-0001 1/1 Running 0 26m
galera-node-0002 0/1 Running 0 1m
galera-node-0003 0/1 Running 0 56s
And after about a minute (each Galera node has to start and sync data from another member), we see the new pods become ready:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 31m
galera-node-0001 1/1 Running 0 27m
galera-node-0002 1/1 Running 0 2m
galera-node-0003 1/1 Running 0 2m
Now that we have a three node cluster, we can re-run the same test as earlier:
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 527282
write: 0
other: 75326
total: 602608
transactions: 37663 (3756.49 per sec.)
queries: 602608 (60103.86 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0247s
total number of events: 37663
Latency (ms):
min: 4.30
avg: 39.88
max: 8371.55
95th percentile: 82.96
sum: 1501845.63
Threads fairness:
events (avg/stddev): 251.0867/87.82
execution time (avg/stddev): 10.0123/0.01
With dramatic results! Our cluster is now able to process 60K queries
per second! How far can we take this? Well, if you noticed our node
count at the start we have five nodes in our k8s cluster, so lets make
our Galera cluster match that:
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 5
The Ansible operator starts growing the Galera cluster...:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 35m
galera-node-0001 1/1 Running 0 32m
galera-node-0002 1/1 Running 0 7m
galera-node-0003 1/1 Running 0 7m
galera-node-0004 0/1 Running 0 38s
galera-node-0005 0/1 Running 0 34s
And again after about a minute or so we have a Galera cluster with five
pods ready to serve queries:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 36m
galera-node-0001 1/1 Running 0 33m
galera-node-0002 1/1 Running 0 8m
galera-node-0003 1/1 Running 0 8m
galera-node-0004 1/1 Running 0 1m
galera-node-0005 1/1 Running 1 1m
Oddly, the fifth node had a problem, but OpenShift retried it after it
failed and it came up and into the cluster. Great!
So let's rerun our same test once again:
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 869260
write: 0
other: 124180
total: 993440
transactions: 62090 (6196.82 per sec.)
queries: 993440 (99149.17 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0183s
total number of events: 62090
Latency (ms):
min: 5.41
avg: 24.18
max: 159.70
95th percentile: 46.63
sum: 1501042.93
Threads fairness:
events (avg/stddev): 413.9333/78.17
execution time (avg/stddev): 10.0070/0.00
And we're hitting 100K queries per second. Our cluster has thus-far
scaled linearly with the number of nodes we've spun up. At this point,
we've maxed out the resources of our OpenShift cluster, and spinning up
more Galera nodes doesn't help:
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 9
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 44m
galera-node-0001 1/1 Running 0 41m
galera-node-0002 1/1 Running 0 16m
galera-node-0003 1/1 Running 0 16m
galera-node-0004 1/1 Running 0 9m
galera-node-0005 1/1 Running 1 9m
galera-node-0006 1/1 Running 0 1m
galera-node-0007 1/1 Running 0 1m
galera-node-0008 1/1 Running 0 1m
galera-node-0009 1/1 Running 0 1m
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 841260
write: 0
other: 120180
total: 961440
transactions: 60090 (5995.71 per sec.)
queries: 961440 (95931.35 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0208s
total number of events: 60090
Latency (ms):
min: 5.24
avg: 24.98
max: 192.46
95th percentile: 57.87
sum: 1501266.08
Threads fairness:
events (avg/stddev): 400.6000/134.04
execution time (avg/stddev): 10.0084/0.01
Performance actually decreased a bit! This shows that MySQL/MariaDB are
pretty resource-intensive, so if you want to continue scaling out the
performance you may need to add more OpenShift cluster resources. But at
this point, our cluster is serving nearly 5x the traffic as when we
originally started it up. Continued tuning of MySQL/MariaDB and Galera
could extend that and allow us to increase performance further. However
the goal here was to show how to create an Ansible operator to control a
very complex, data-oriented application.
Scaling the cluster down
Since those extra nodes aren't helping out (other than providing a bit
more redundancy in the event of a failure), lets scale the cluster back
down to five nodes:
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 5
After a short while, we see the operator begin to terminate pods that
are no longer required:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 46m
galera-node-0001 1/1 Running 0 43m
galera-node-0002 1/1 Running 0 18m
galera-node-0003 1/1 Running 0 18m
galera-node-0004 1/1 Running 0 11m
galera-node-0005 1/1 Running 1 11m
galera-node-0006 0/1 Terminating 0 3m
galera-node-0007 0/1 Terminating 0 3m
galera-node-0008 0/1 Terminating 0 3m
galera-node-0009 0/1 Terminating 0 3m
Disaster recovery
Now, let's add some chaos. Looking at our first worker xx-yy-zz-2, we can see which pods are running on the node:
$ oc describe node ec2-xx-yy-zz-2.us-east-2.compute.amazonaws.com
...
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
openshift-monitoring node-exporter-bqnzv 10m (0%) 20m (1%) 20Mi (0%) 40Mi (0%)
openshift-node sync-hjtmj 0 (0%) 0 (0%) 0 (0%) 0 (0%)
openshift-sdn ovs-55hw4 100m (5%) 200m (10%) 300Mi (4%) 400Mi (5%)
openshift-sdn sdn-rd7kp 100m (5%) 0 (0%) 200Mi (2%) 0 (0%)
test galera-node-0004 0 (0%) 0 (0%) 0 (0%) 0 (0%)
...
So galera-node-0004 is running here, along with some other
infrastructure bits. Lets restart it from the AWS EC2 console and see
what happens...
$ oc get nodes
NAME STATUS AGE
ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-2.us-east-2.compute.amazonaws.com NotReady 1d
ec2-xx-yy-zz-3.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-4.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-5.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-6.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-7.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-8.us-east-2.compute.amazonaws.com Ready 1d
Eventually, we see galera-node-0004 enter an unknown state:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 50m
galera-node-0001 1/1 Running 0 47m
galera-node-0002 1/1 Running 0 22m
galera-node-0003 1/1 Running 0 22m
galera-node-0004 1/1 Unknown 0 16m
galera-node-0005 1/1 Running 1 16m
And in a while the pod will be terminated, after which the Ansible
operator will restart it:
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 55m
galera-node-0001 1/1 Running 0 52m
galera-node-0002 1/1 Running 0 27m
galera-node-0003 1/1 Running 0 27m
galera-node-0004 1/1 Running 1 1m
galera-node-0005 1/1 Running 1 21m
... and our cluster is back to its requested capacity!
Cleanup
Since this is a test we'll want to clean up after ourselves. When we're
done we use the delete_operator.sh script to remove the custom resource
and the operator deployment:
$ ./delete_operator.sh
galeraservice.galera.database.coreos.com "galera-example" deleted
deployment.apps "galera-ansible-operator" deleted
In a couple of minutes, everything is gone:
$ oc get all
NAME DOCKER REPO TAGS UPDATED
is/galera-ansible-operator docker-registry-default.router...:5000/test/galera-ansible-operator latest 4 hours ago
Summary
The Galera operator is a work in progress and is most definitely not
ready for production. If you'd like to view the playbooks themselves,
you can see the code here:
https://github.com/water-hole/galera-ansible-operator
We're going to be continuing development on this with the goal of
making it the de facto example for other data storage applications.
Thanks for reading!